How to design Tiktok: System design interview


12 min read
How would you design a backend for an application like TikTok? This is one of the most popular system design questions. Keep in mind that TikTok could be replaced with Instagram, YouTube, or other similar services, and the key design considerations would remain largely the same. However, there will be some trade-offs that you would need to address differently.
Structure to the answer
In my opinion, questions like these can not be answered well in 1 hour. So in order to cover it in one hour there are two routes that you and interviewer may take. Focus on breadth of the design, talk about all different components, interactions and such. Or the interviewer might want to focus on one specific component and discuss that in greater detail. For example in some cases interviewer might focus more on security, large data storage to co-location more than anything else. I can this Breadth vs Depth. You do not know beforehand how the interview will go, so it is better to give it a structure and talk about this structure with your interviewer beforehand.
Structure to the answer
I like to divide design problems like these in following steps:
Understand the functional requirements and how they translate into some back of envelop math.
Identify key constraints of the system you are designing.
Identify the optimizations and performance imperatives you want to consider in you design
Outline the broader online components.
Outline the broader non critical components.
Outline the communication between the key components.
Focus on database schema and entity design
Focus on key API contracts.
Identify operational and monitoring processes that you need to build.
Go deeper into implementation designs such as Class designs.
Now, this is not a hard structure which means depending on the interviewer, time and how it proceeds you might have to adjust this or articulate it differently to the interviewer but keeping these 10 points in your head is valuable.
Step 1: Understanding the requirements and doing back of the envelop math.
Understand the difference between just ordinary programmers and senior engineers. Senior folks deal with ambiguous problems better. They are not task focused. They understand the larger goal and try to figure out path to achieve it. These are the people who break down barriers so juniors and wade through.
When you are answering this system design question, you need to act like a senior engineer who is about to break down new barriers. Hence ask questions. For example, in this case, everyone knows what Tiktok is but it is also an app with thousands of features. When you are designing Tiktok, it is better to define what Tiktok is. It is a common set of features in an app that you and interviewer agree on which will determine the constraints in your design.
What is Tiktok ?
Start with some assumptions and ask the interviewer to stop you if you are making wrong assumptions.
An app that allows users to sign-in and upload videos.
- App refers to Android and iOS apps. There might be other clients too like Web and TV which need to be supported but their design is will not be covered here.
An app that allows users to browse through a lot of videos that other people might have uploaded based on their interests.
It is a global app with 1B monthly active users.
The app also serves ads but for the sake of this design we keep it out.
Videos must load quickly and should be highly personalized.
Each video has properties like shares, likes, views etc. that are public.
The back of envelope math
This is an interesting stage because a lot of these numbers might not be public but you can always start with some assumptions. In this sort of math I generally go for these numbers
How many active users on an average at any second are
What might be the peak load ?
What kind of QPS we are looking at and what kind of storage that it leads to ?
Now, one way I do this math is by remembering some upperbounds on public numbers. I know that Google gets around 70K search queries per second. Given that google search is lot common, I expect most other activities to be less trafficked than Google. It is a fair assumption to make.
So I quickly scribbled this math on whiteboard.
1 B users means very little in reality. What matters is how many active users. I made an assumption that Titktok might have 1/7th of Google's traffic. Around 10K users actively swiping through videos and may be 5% of them actually trying to upload videos. 5% in my opinion is a very very gross exaggerated number but perhaps it is better err on the side of overestimation here.
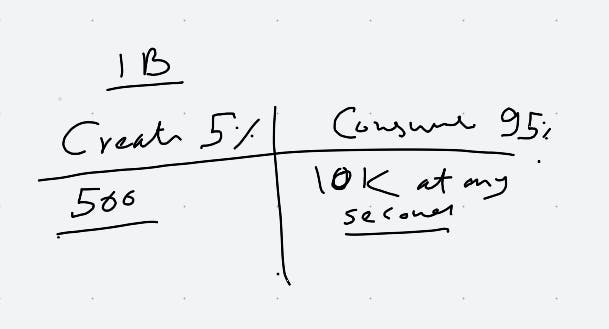
After writing these numbers I actually looked up. Tiktok as 50M daily active users which when spread out evenly on 24*60*60 comes to 50,000,000/86400. This comes to around 600 QPS. However in reality, traffic is no uniformly distributed and we can assume 80% of your traffic will be distributed in 20% of time so you basically do the following math :
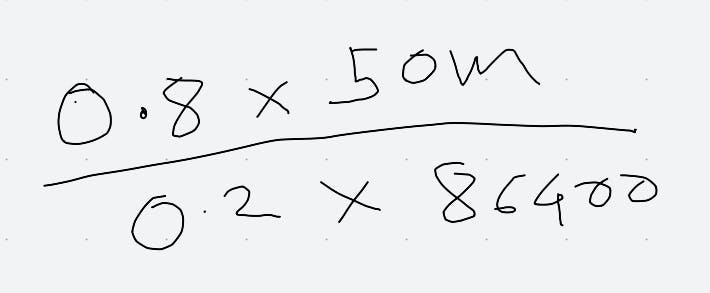
This comes to around 2314 QPS.
This means my estimations were off by a factor of 5. While this is terrible, it is an upper bound. Clearly our assumption that Tiktok's traffic was 1/7th of Google's traffic was overestimation but that is fine.
We can say we want to support around 3000 QPS on average and 10K at peak.
If you are already in consumer app business you might know that weekend traffic is generally lower, and on certain days in they year the internet traffic is lot higher. During the day time certain times such as morning 9am and evening 6-9pm has higher internet traffic.
Consumption focused apps like Youtube, Instagram and Tiktok often have higher QPS needs during special times like Superbowl, Oscars etc.
So it boils down to this math :
| Average QPS | Peak | |
| Consuming Videos | 3000 | 10000 |
| Uploading Videos | 150 | 150 (This is same as average because we have already overestimated the average QPS by large factor) |
How many videos are being consumed ?
QPS tells us little about actual video consumption. We can assume that out of those 3000 QPS all those requests eventually end up downloading an entire video. Again an overestimation but fair one to make.
Bandwidth requirements
Now that we have resolved the QPS aspect we come to the storage and bandwidth requirements which are especially important for anything that involves videos.
Average video on Tiktok is around 60s long and around 13MB. This information is something I looked up, but without it I would have probably estimated it to be around 30s and 20 MB.
What this means is we can expect around 150*13MB of storage being required per second. This is around 2GB of storage expansion every second.
In terms of consumption 3000*13 comes to around 40GB of downloading per second! We are dealing with an exceptional storage requirements here.
This means Tiktok needs around 200K GB storage space every day this is around 64 petabytes per year.
Whenever you are dealing with a storage heavy, remember that you will have to split your storage design into blob storage and non-blob storage.
Each video will have some metadata associated with it such as who uploaded it, who saw it and so on. We call this video metadata. This is likely to be lot smaller compared to the 13MB video size. May be in few KBs.
So we can say around 100MB of metadata gets generated every second per 2GB of video upload.
Other storage requirements
We want to log every user action and later process it.
We want to pre-build user recommendations and store them etc.
Key constraints and performance optimizations
Now we have sufficient idea about the functional requirement and some math that tells us about the scale we can talk about some constraints that this imposes on us or the constraints we impose on the design to save money.
We need a blob storage for videos which increases with time pretty significantly.
We need co-location of data for our users, data that a user is likely to consume must be stored closer to the user and so on.
We need a personalized feed of every user.
We need to save bandwidth for our systems as well as for our users.
The feed must be generated offline so we do no struggle to generate it in real time.
Since the new data being generated is very high, we need to keep the feed very fresh.
Design
Critical components
I think at this stage we have sufficient information to come up withe some basic components. As a rule of thumb any good system basically takes a beaten path and then makes customizations as we go forward.
No matter what system you are designing, certain things are pretty common everywhere. So here is a simple design I have that generally works for nearly all system design issues.
It is important that you understand what these problems are.
Clients are separate component in themselves and have their own design decisions to be made. We wont go there.
A Load balancer + API gateway is a system that acts as "front door" for all your incoming requests. It does basic security things like TLS, HTTP 2.0, routing request to right application server and so on. It will also detect DDOS attacks, do API rate limiting and so on. Typically you do not build this system yourself but rather simply rent out some cloud service or a third party provider.
A backend for frontend is the real front end api that your clients can talk to. This is where you decide you API interface. It solves following problems:
It separates your backend apis from the apis that your clients see. Updating clients like apps is harder so you want to get the api right the first time while keeping the backend apis separate.
It is easier to scale these BFFs than backend systems and we can decide what data is passed forward and what is redacted. Thus saving bandwidth.
Identity micro-service is something that every app needs. This is basically where your users sign up and authenticate.
Storage:
Nearly all apps need some kind of database.
Relational database where your entity relationship is clear and well understood and makes sense. Typically users table, roles, ACLs, etc. where consistency and atomicity is critical.
NoSQL where data structure might not be well defined but you want to evolve it as it goes, also data changes frequently and consistency etc. might not be that critical and relationships are not important.
For example a user's precomputed feed can be stored in NoSQL.
Blob storage. Like Amazon S3 or Google Cloud Storage. This is for large files, typically videos and images.
Non critical components
Non critical components here means not so critical for the initial design itself. These are the components where specific design trade offs might not be instantly visible and clear. But we know that these components should exist.
Let us expand our above graph with this.
Any large system would need following components
Some way to run long running jobs. For example encoding videos or images.
Process logs to do monitoring and alerts.
Some way to connect to the outside world like Twilio (to send text messages), Sendgrid (to send emails) etc.
Tiktok specific components
Now we come to the most important part. The interviewer asked you about Tiktok because he/she wanted to know about some Tiktok specific things. Which in this case is likely
How you deal with video content
How you handle user feed
How you handle performance, videos should load fast etc.
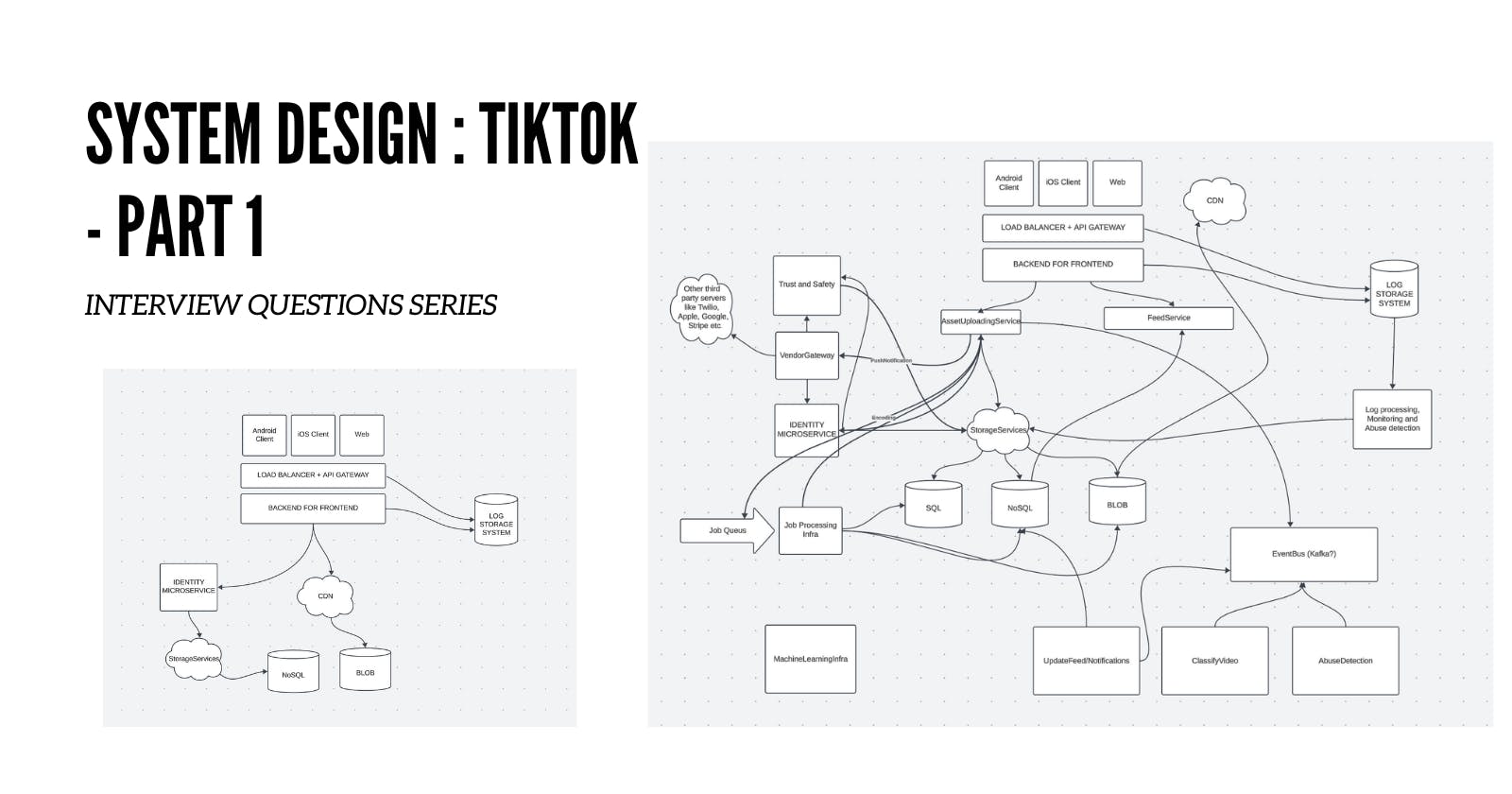
Here is an updated diagram
An AssetUploadingService will simply take a file from user as input and decide what to do with it. The happy path is just add it to blob storage and allow other systems to do their work associated with it. Here is a sequence diagram.
Communication between different component
Here when user uploads a file, the asset Uploading service will first check if the user has right to upload file. Based on the video metadata it might detect basic abuse such as copyright violation, existing video etc. For example client can send us MD5 hash of the video along with the video itself. The hash can be used to detect that the video is already present in our assets.
What does AssetUploadService do ?
Provide multiple APIs to upload a video from client.
There are tradeoffs but best is for the user to first call an API
/PrepareForUpload
Give hash of the file
Size of the file etc.
/UploadAsset
Store file to blob storage
storeAsset Id with the user
Create an event for Event bus for the rest of the systems to react in non real time.
The client first provides us with sufficient information to detect if the video is worth uploading or not. Some information is cheaper to compute on client. For example, hash of the asset can tell us that the file is already present in our blob storage, we can then simply reuse it.
As soon as a new video is uploaded it creates and event that other subsystem can listen to and respond to. This includes
Re-encode the video and push its different versions on CDN
Update user's profile to reflect the video they just uploaded
Send out email and push notifications
Inform the feed computation subsystem to update their feeds.
This diagram gives a more comprehensive picture of this system and as you can tell it is fairly complicated.
You can talk about how to break this system into teams. For example I would have a large storage services team providing Blob, Sql and NoSql read/write interfaces. This will be a large team which will also handle things like video/audio encoding.
Identity team will focus on authentication, user profile and social graph.
Feed team will focus on building feed and updating it.
Infra team will build Kafka powered communication system that helps others do their work.
Coming up next
We will discuss the entity design and API contracts in next post.
